Nov25

The dream of Artificial General Intelligence (AGI)—a machine capable of matching human cognitive flexibility—has driven computer science since the Dartmouth Workshop in 1956. For decades, this pursuit was divided: the Symbolic AI tradition focused on formal rules and logic, often failing to interface with the messy, continuous real world; simultaneously, the Connectionist (Deep Learning) tradition excelled at perception and pattern recognition but lacked intrinsic causality and high-level reasoning. The advent of powerful Large Language Models (LLMs) like Gemini, with their vast store of codified human knowledge, reignited the AGI debate but highlighted a persistent gap: how does a text-based brain effectively govern a body in the physical world?
This work directly tackles that gap. Inspired by the architectural pillars proposed by influential thinkers such as Yann LeCun, the system presented here demonstrates true modularity. It transcends the limitations of monolithic LLMs by integrating Vision Joint-Embedding Predictive Architecture (V-JEPA) for real-world sensing, a Predictive Latent Dynamics Model (PLDM) for internal causal simulation, and the advanced reasoning of Gemini 3 Pro for operational oversight. By combining these specialized modules, the architecture aligns with the five core AGI pillars, resulting in a unified, agentic system capable of coherent action in a complex environment such as autonomous flight operations. This integration represents a critical evolutionary leap from abstract knowledge processing toward embodied, causal, and safe decision-making.
The successful refactoring of the code showcases the integration of an LLM (Gemini 3) with a perception system (V-JEPA) and a dynamics model (PLDM) to conceptually demonstrate the Five AGI Pillars for an autonomous flight agent. The entire notebook structure—from data ingestion and model training to the final Gemini assessment—is designed to address these fundamental requirements of next-generation AI.
Pillar Alignment: The system explicitly uses a Latent Dynamics Predictor (the "World Model") to learn the causal relationships of aircraft states in a hidden, compact space. Code Implementation:
Pillar Alignment: The system moves beyond memorizing patterns by building a predictive model that understands cause-and-effect ($\text{Action} \to \text{Next State}$) in the latent space. Code Implementation:
Pillar Alignment: The system is inherently modular, separating Perception (V-JEPA for feature extraction), High-Level Reasoning (Gemini LLM for operational assessment), and Causal Planning (Latent Dynamics Predictor). Code Implementation:
Pillar Alignment: The agent is embodied through its visual input (V-JEPA processing a video from an assumed aircraft perspective) and its reliance on physical state data (ADS-B telemetry). It focuses on what matters—the operational context. Code Implementation:
Pillar Alignment: This describes a hybrid system, demonstrated here by combining the mathematically rigorous Cognitive World Model (the latent state predictor) with a Symbolic Reasoning system (the Gemini LLM). Code Implementation:
The architecture demonstrated by integrating V-JEPA, the Predictive Latent Dynamics Model, and Gemini 3 Pro's advanced reasoning represents a pivotal shift from narrow AI utility to the design of truly agentic AGI systems. The success of this modular approach validates the need to combine specialized components: V-JEPA for what is seen, PLDM for what will happen, and Gemini for what should be done.
By separating these cognitive functions—perception, internal modelling, and high-level command—the system gains robustness, transparency, and, crucially, causal intelligence. This framework provides a robust foundation for building self-supervised, self-correcting agents capable of safely navigating the complexities of the real world, from flight control to complex industrial automation. The core challenge of AGI is not just generating language or classifying images, but orchestrating these functions coherently under real-world constraints. This project offers a compelling solution, establishing a modular paradigm that will define the next generation of autonomous intelligence.
Keywords: Agentic AI, Generative AI, Predictive Analytics
 No More Hold Music: How AI is Fixing the UK’s Customer Service Crisis
No More Hold Music: How AI is Fixing the UK’s Customer Service Crisis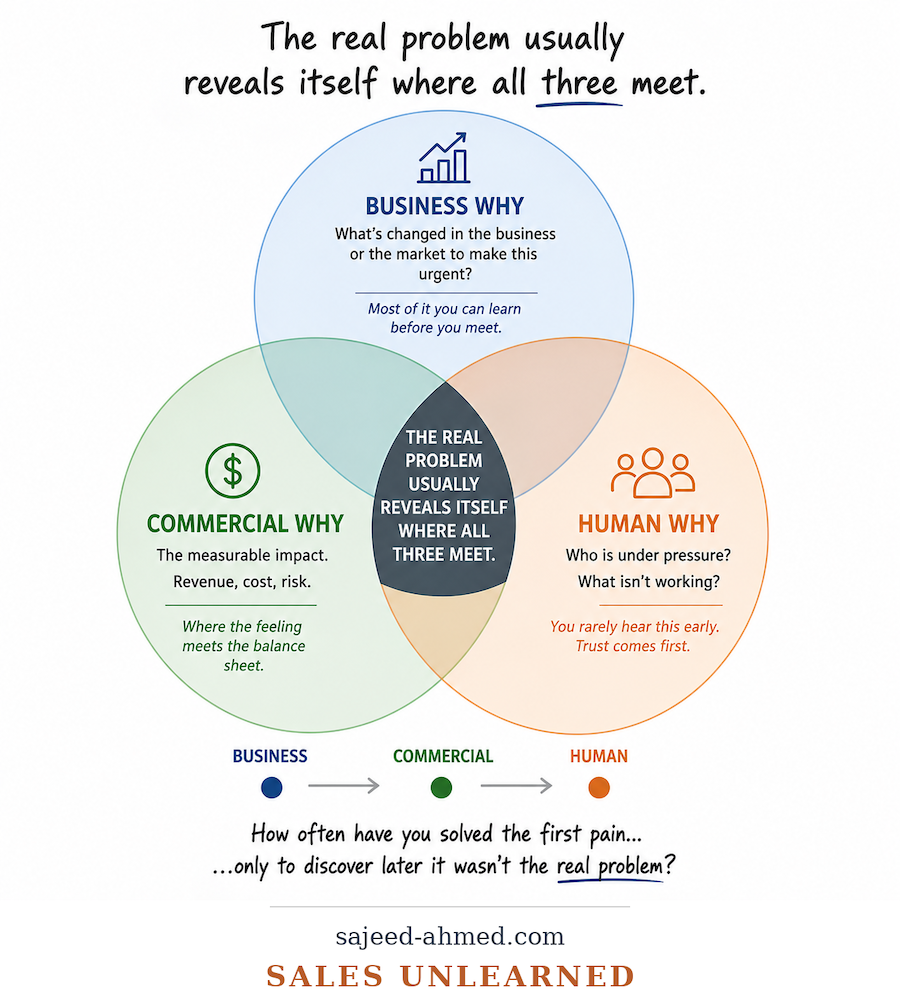 Why the First Customer Pain Is Rarely the Real Problem in Enterprise Sales
Why the First Customer Pain Is Rarely the Real Problem in Enterprise Sales The Missing Middle: Why Privately Held Companies Have Lost Their Mid-Career Talent
The Missing Middle: Why Privately Held Companies Have Lost Their Mid-Career Talent When Products Can't Reach the Market
When Products Can't Reach the Market Friday’s Change Reflection Quote – Saeculum Leadership – Future Generations Inherit Today's Leadership Decisions
Friday’s Change Reflection Quote – Saeculum Leadership – Future Generations Inherit Today's Leadership Decisions















