Nov22

The colossal demand for specialized computing power defines the modern era of artificial intelligence. Historically, hardware constraints limited the ambition of neural networks; today, the capabilities of state-of-the-art Large Language Models (LLMs) are a direct measure of the infrastructure on which they are trained. This convergence of algorithmic sophistication and raw compute has driven a high-stakes technological race, culminating in Google’s deep investment in its custom silicon. The launch of Gemini 3 Pro represents the pinnacle of this decades-long strategy: a natively multimodal model whose superior intelligence and groundbreaking performance are rooted in a deeply integrated, full-stack co-design. This analysis, proven by a live code execution environment running the gemini-3-pro-preview On a specialized Tensor Processing Unit (TPU v6 lite), it demonstrates how hardware-software synergy unlocks frontier performance in complex reasoning, native multimodality, and agentic coding.
Google's strategic reliance on TPUs began years before Gemini, establishing a clear lineage of foundation models built on this custom silicon. This vertical integration provided the necessary compute at massive scale, powering successive generations of AI breakthroughs:
T5, LaMDA, and PaLM: These influential LLMs, including the dense PaLM 540B model trained on massive TPU v4 Pods (up to 6,144 chips), proved the efficiency and scalability of the TPU architecture for large-scale language model pre-training.
Gemini Family (1.0, 2.5, 3 Pro/Flash): The current generation, built on the sparse Mixture-of-Experts (MoE) architecture, was trained on the newest TPUs (v5e, v5p, and Trillium), underscoring Google's control over the foundational AI layer.
The intelligence of Gemini 3 Pro is inseparable from its hardware. Unlike models relying on general-purpose GPUs, Gemini 3 Pro was trained exclusively on Google’s custom Tensor Processing Units (TPUs). This provides a crucial full-stack advantage: engineering the model architecture, the compiler, and the hardware together for efficiency.
Specifically, Gemini 3 Pro uses a sparse Mixture-of-Experts (MoE) architecture that dramatically scales capacity without proportionally increasing per-token computation. The immense scale and high-communication demands of MoE models require specialized networking. Google's TPU architecture, with its high-speed Inter-Chip Interconnect (ICI) and massive TPU Pods, is perfectly tailored to handle this sparse computation, enabling:
Efficiency at Scale: TPUs address the memory-bound challenges of MoE models, enabling high-intelligence models to train cost-effectively.
Performance: The inference model (gemini-3-pro-preview) running on a smaller accelerator like the TPU v6 lite retains the high-speed, low-latency performance essential for real-time applications.
The exclusive use of TPUs for training establishes the hardware as a non-trivial enabler of the model’s unique capabilities.
The resulting capabilities, tested within the inference environment, prove the success of this co-design. The model demonstrated:
Complex Reasoning: Generating a time-constrained travel itinerary that balances four conflicting constraints (time, budget, interests, luggage) requires deep, multi-step planning.
Native Multimodality: Analyzing the Cybertruck image by fusing visual data with external text knowledge (the production milestone) to provide a single, cohesive explanation.
Agentic Coding: Successfully performing "vibe coding"—generating a complete, styled HTML/CSS/JavaScript web application from a natural language request.
Ultimately, Gemini 3 Pro marks a shift in the landscape of artificial intelligence. Its demonstrated excellence is the inevitable outcome of Google’s strategic vertical integration. By co-designing the MoE model architecture with its custom TPU hardware—from the massive training pods to the inference-optimized TPU v6 lite accelerators—Google has established a new standard for efficiency and capability. The full-stack approach minimizes operational costs and optimizes the model for its exact hardware. Moving forward, the race for frontier AI will be defined by the ability to control and co-engineer the entire hardware-software ecosystem, positioning the seamless deployment of Gemini 3 Pro on a dedicated TPU as the blueprint for the next generation of scalable, intelligent systems.
Keywords: Predictive Analytics, Generative AI, Agentic AI
 No More Hold Music: How AI is Fixing the UK’s Customer Service Crisis
No More Hold Music: How AI is Fixing the UK’s Customer Service Crisis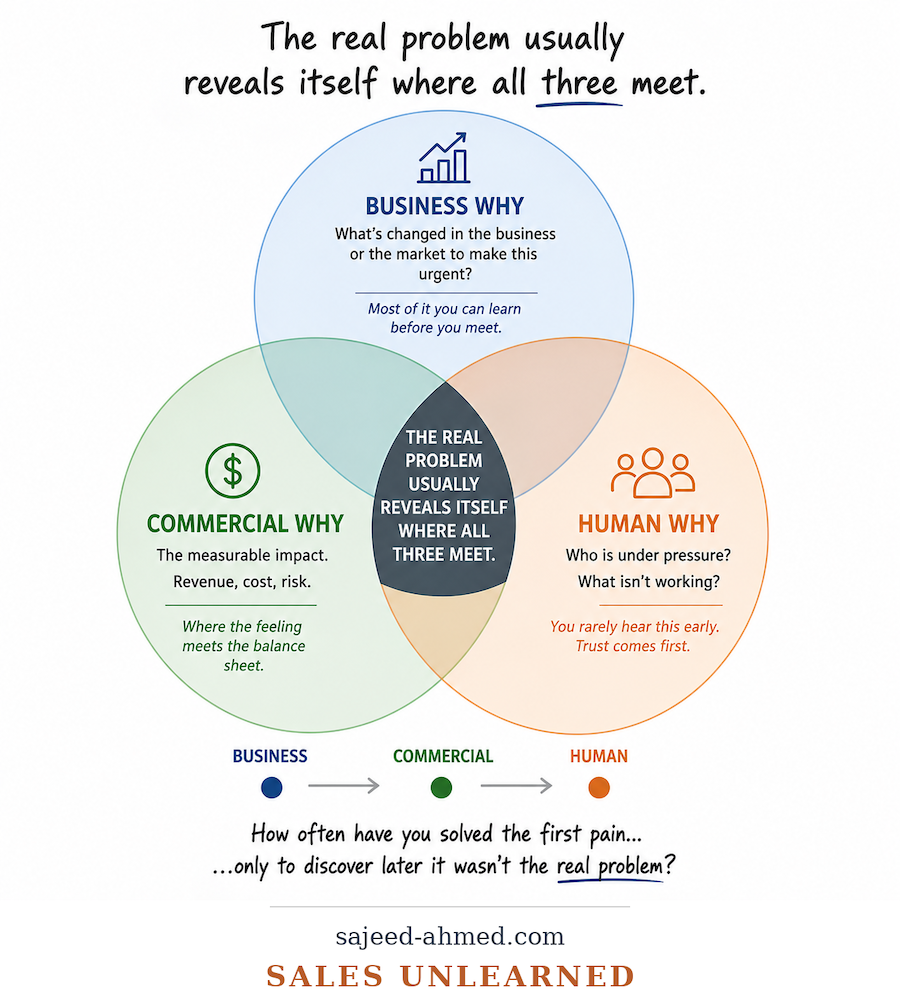 Why the First Customer Pain Is Rarely the Real Problem in Enterprise Sales
Why the First Customer Pain Is Rarely the Real Problem in Enterprise Sales The Missing Middle: Why Privately Held Companies Have Lost Their Mid-Career Talent
The Missing Middle: Why Privately Held Companies Have Lost Their Mid-Career Talent When Products Can't Reach the Market
When Products Can't Reach the Market Friday’s Change Reflection Quote – Saeculum Leadership – Future Generations Inherit Today's Leadership Decisions
Friday’s Change Reflection Quote – Saeculum Leadership – Future Generations Inherit Today's Leadership Decisions















