Sep09

Interesting look at a recent research article called "VFLGAN: Vertical Federated Learning-based Generative Adversarial Network for Vertically Partitioned Data Publication" by Xun Yuan, et. al 2024. Here is the link to the full 19-pg article: https://petsymposium.org/popets/2024/popets-2024-0144.pdf
Some of the key points on the Vertical Federated Learning-based Generative Adversarial Network (VFLGAN) for vertically partitioned data publication with a view from SciSpace's GPT wrapper analyzing research articles, seems like a useful tool:
Improved Data Quality: VFLGAN significantly enhances the quality of synthetic data compared to its predecessor, VertiGAN. The experimental results indicate that the synthetic dataset generated by VFLGAN is 3.2 times better in quality, as measured by the Frechet Distance, which is a metric used to assess the similarity between two probability distributions.
Addressing Correlation Preservation: One of the critical issues identified with VertiGAN was its ineffectiveness in preserving the correlation among attributes belonging to different parties. VFLGAN addresses this limitation, ensuring that the relationships between different data attributes are better maintained in the synthetic dataset.
Differential Privacy Mechanism: The paper introduces a more efficient and effective Gaussian mechanism within VFLGAN to ensure that the synthetic dataset adheres to differential privacy standards. This is crucial for protecting individual data points while still allowing for meaningful data analysis.
Privacy Auditing Scheme: In addition to providing a differential privacy guarantee, the authors propose a practical auditing scheme. This scheme utilizes membership inference attacks to estimate potential privacy leakage from the synthetic dataset, thereby enhancing the understanding of privacy risks associated with synthetic data publication.
Relevance in AI Development: The findings underscore the importance of high-quality datasets in training AI models, especially in light of privacy regulations like GDPR. The ability to generate synthetic datasets that maintain data quality and privacy is vital for advancing AI research and applications.
In summary: this new approach might help model-building while addressing privacy concerns.
By Dan Banas
Keywords: Analytics, AI, Business Strategy
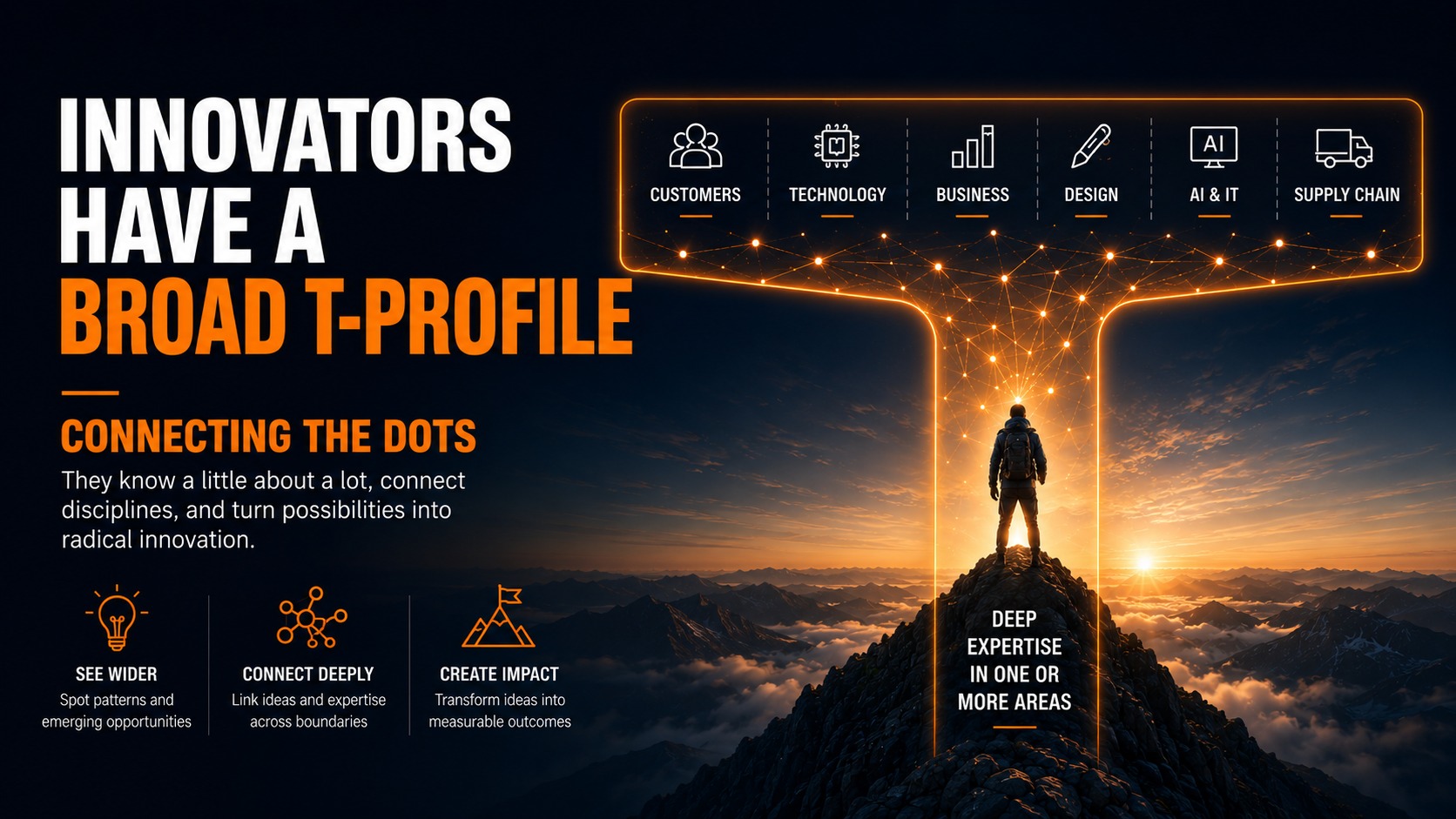 Radical Innovation Happens Between the Dots
Radical Innovation Happens Between the Dots Connection Crisis: Leaders Are Lonely Too
Connection Crisis: Leaders Are Lonely Too People don’t resist change. It’s uncertainty that scares people.
People don’t resist change. It’s uncertainty that scares people.  Friday’s Change Reflection Quote – Saeculum Leadership – Leaders Transform by Redesigning Systems
Friday’s Change Reflection Quote – Saeculum Leadership – Leaders Transform by Redesigning Systems The Corix Partners Friday Reading List - July 31, 2026
The Corix Partners Friday Reading List - July 31, 2026















