Aug25

The era of artificial intelligence is defined by the colossal power of Large Language Models (LLMs), magnificent neural networks that replicate the nuances of human language. Yet, the journey from their vast, generalized intelligence to specialized, practical applications is fraught with immense computational demands. Our recent endeavour—fine-tuning a 20-billion-parameter GPT-OSS-20B model on a formidable 4x H100 GPU cluster from Lambda.ai, meticulously guided by the finetuning_h100_fp8_lambda.py script—serves as a compelling testament. It vividly demonstrates how the strategic convergence of sophisticated algorithmic efficiency and cutting-edge hardware is not just an advantage but a necessity, unlocking unprecedented capabilities in the relentless pursuit of advanced AI.
The selection of GPT-OSS-20B for this fine-tuning endeavour is particularly significant. As a 20-billion-parameter model, it provides a robust foundation for a wide range of natural language tasks. The availability of such a potent model, especially from an entity like OpenAI that has advocated for both closed and increasingly open approaches to AI development, marks a pivotal shift in the field.
The term 'open source' implies that its architecture, weights, or at least substantial insights into its workings, are accessible to the broader research community. This open accessibility democratizes advanced AI capabilities, empowering researchers and developers to build upon and specialize state-of-the-art LLMs without starting from scratch.
The act of fine-tuning GPT-OSS-20B is not just a technical exercise; it represents a transformative pathway to maximizing the utility and impact of such a powerful foundational model. While a pre-trained LLM like GPT-OSS-20B possesses a vast general understanding of language, it lacks specific knowledge or stylistic nuances required for specialized applications. Fine-tuning bridges this gap, adapting the model's core capabilities to perform exceptionally well on domain-specific tasks or to adhere to particular interaction styles. This process allows organizations and individuals to leverage the massive investment in pre-training, customizing it for their unique needs without having to build a large model from the ground up. The open-source nature of GPT-OSS-20B amplifies this importance, as it enables a broader community to collectively refine and deploy these models, pushing the boundaries of what is possible in AI across countless sectors.
The choice of Lambda.ai's infrastructure, specifically their 4x H100 GPU cluster, was instrumental to the success of this fine-tuning project. NVIDIA's H100 Tensor Core GPUs are purpose-built for accelerating AI workloads, offering significant advantages in both computational speed and memory capacity. Each H100 GPU provides 80 GB of HBM3 memory, which is critical for accommodating the considerable parameters of models like GPT-OSS-20B. Furthermore, the H100's architecture, including its advanced Tensor Cores and NVLink interconnections, facilitates high-speed data transfer and parallel processing across multiple GPUs. This capability allowed us to distribute the immense computational burden of the 20-billion parameter model across the four GPUs, ensuring that device_map='auto' could efficiently shard the model and optimize resource utilization. The robust and scalable environment provided by Lambda.ai enabled us to leverage these hardware advantages fully, transforming a theoretically challenging task into a practical and achievable endeavour.
The finetuning_h100_fp8_lambda.py script exemplifies a sophisticated approach to making this task feasible. It strategically employs Parameter-Efficient Fine-Tuning (PEFT), specifically Low-Rank Adaptation (LoRA), to dramatically reduce the number of parameters that need to be trained. Instead of updating all 20 billion parameters, LoRA introduces small, trainable matrices alongside the original weights, effectively fine-tuning only a minuscule fraction (in our case, 0.0190%) of the model. This ingenious technique drastically cuts down memory requirements and speeds up convergence, transforming an otherwise intractable problem into a manageable one.
Complementing LoRA, the script utilizes mixed-precision training with fp16, allowing most computations to occur in a lower-precision format. This is a vital optimization for the H100 GPUs, as they are highly optimized for float16 operations, resulting in faster training times and further memory savings, which is critical when every gigabyte of VRAM counts. The script's use of device_map='auto' intelligently distributes the substantial model across all available H100 GPUs, a crucial feature for models that exceed the capacity of a single GPU. It then leverages the SFTTrainer from Hugging Face TRL to streamline the supervised fine-tuning process.
The entire fine-tuning process was meticulously monitored on the Lambda.ai system with four H100 GPUs, as visually confirmed by nvtop (see nvtop.png), which tracked images and the distinctive lambda-hostname in the terminal prompt. This close observation provided critical insights throughout our iterative optimization.
Initially, our journey encountered formidable challenges, including a "CUDA out of memory" error during the evaluation phase—a common bottleneck when pushing the limits of GPU capacity. A ValueError compounded this during TrainingArguments setup, stemming from misaligned save_steps and eval_steps. These issues necessitated a meticulous review and adjustment of our configuration. We strategically shifted from bf16=False to fp16=True for mixed-precision training, precisely tuned batch sizes, and meticulously aligned our saving and evaluation steps.
The culmination of these efforts was a remarkably swift and successful training run. The provided logs confirmed all four GPUs were actively engaged, with VRAM usage on GPUs 2 and 3 approaching their maximum capacity (79.19 GiB), typical for efficiently sharded models. The training process completed 0.1 epochs in less than seven minutes, with the final reported training loss dropping to an impressive 0.0001 and token accuracy reaching 1.0.
While these training metrics demonstrate robust learning and adaptation to the Alpaca dataset, the presence of eval_strategy="steps" further confirms that the model's performance on a validation set was continuously monitored, providing a crucial safeguard against potential overfitting. This rapid convergence, coupled with the efficient utilization of nearly all VRAM on the H100s, underscores the profound impact of combining algorithmic optimizations with specialized hardware.
The final training metrics(see metrics.png) reported at the end of the session showed an extremely low loss of 0.0001 and a mean token accuracy of 1.0. These figures indicate that the model effectively learned to predict the training data with minimal error and achieved 100% accuracy on the last reported batch. While such results demonstrate the success of the training phase and the model's strong adaptation to the new dataset, it also raises the possibility of overfitting. Overfitting occurs when a model learns the training data too well, potentially memorizing noise and specific examples rather than generalizing underlying patterns. This can lead to reduced performance on new, unseen data. Therefore, while the training loss and accuracy are excellent indicators of the model's learning on the provided data, a comprehensive evaluation would also consider the validation loss (eval_loss) to ensure robust generalization to new examples. Setting the eval_strategy to "steps" confirms that the model's performance on the validation set was monitored during the run, providing a crucial check against overfitting.
The fine-tuning of a 20-billion-parameter LLM like GPT-OSS-20B on a 4x H100 GPU cluster is more than just a technical achievement; it's a profound statement about the future of AI. This endeavour, powered by intelligent techniques like LoRA and mixed-precision training, unequivocally demonstrates that the path to advanced AI lies in the strategic convergence of sophisticated algorithms and purpose-built hardware. By transforming the previously insurmountable challenge of adapting colossal models into a rapid and efficient process, we unlock unprecedented accessibility and impact for AI across all sectors. This synergy empowers rapid iteration and deployment, accelerating the transition of theoretical AI capabilities into tangible, transformative solutions that will redefine industries and elevate human potential. Critically, as even corporate giants begin to recognize, fostering an open-source community around AI is increasingly seen as the most direct route to achieving superintelligence faster, collectively accelerating progress beyond what any single entity could achieve.
Keywords: Predictive Analytics, Generative AI, Open Source
 No More Hold Music: How AI is Fixing the UK’s Customer Service Crisis
No More Hold Music: How AI is Fixing the UK’s Customer Service Crisis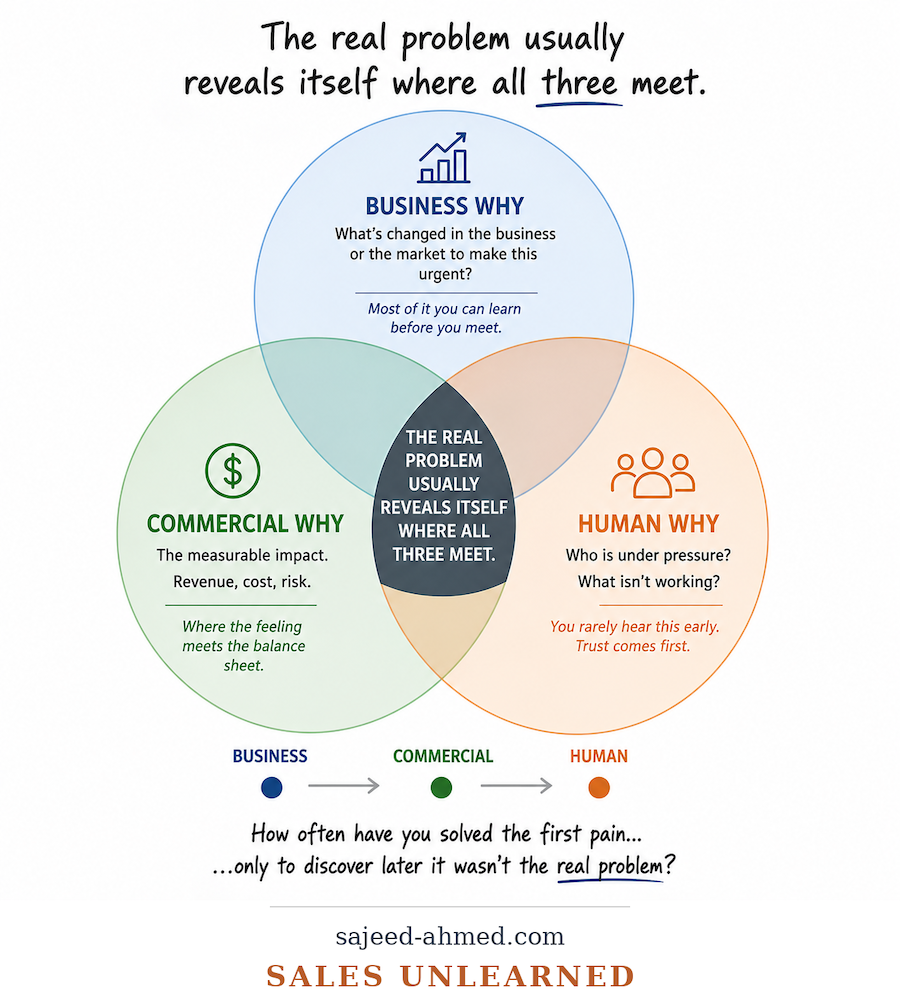 Why the First Customer Pain Is Rarely the Real Problem in Enterprise Sales
Why the First Customer Pain Is Rarely the Real Problem in Enterprise Sales The Missing Middle: Why Privately Held Companies Have Lost Their Mid-Career Talent
The Missing Middle: Why Privately Held Companies Have Lost Their Mid-Career Talent When Products Can't Reach the Market
When Products Can't Reach the Market Friday’s Change Reflection Quote – Saeculum Leadership – Future Generations Inherit Today's Leadership Decisions
Friday’s Change Reflection Quote – Saeculum Leadership – Future Generations Inherit Today's Leadership Decisions















