Unlock access to Thinkers360 AI to fast-track your search for analysts and influencers.
This feature is available for Enterprise Lite and Enterprise Members Only.
You have been temporarily restricted. Please be more thoughtful when adding content for your portfolio. Your portfolio and digital media kit and should be reflective of the professional image you wish to convey. Accounts may be temporarily restricted if we receive reports of spamming or if the system detects excessive entries.
Membership
Publish your original ideas on the Thinkers360 platform!
This feature is available for Pro and Pro-Plus Members Only.
Speaker Bureau functionality whereby individuals can be featured speakers within our Speaker Bureau service and enterprises can find and work with speakers.
This feature is available for Pro, Pro-Plus, Premium and Enterprise Members Only.
Highlight your featured products and services within our company directory for enhanced visibility to active B2B buyers worldwide.
This feature is available for Pro, Pro Plus, Premium and Enterprise Members Only.
Publish on the Web’s #1 Thought Leadership Blog.Join the elite. Ranked the top thought leadership blog by Feedspot (2021–2025), Thinkers360 offers you more than just a platform - it offers authority. Share your insights with our community and tap into a combined network of over 100M followers through our peer-to-peer marketplace.
You’ve reached your daily limit for entering quotes. Please only add personally-authored content which is reflective of your digital media kit and thought leadership portfolio.
Thinkers360 Content Library
For full access to the Thinkers360 content library, please join ourContent Planor become a contributor by posting your own personally-authored content into the system viaAdd PublicationorImport Publication.
Dashboard
Unlock your personalized dashboard including metrics for your member blogs and press releases as well as all the features and benefits of our member plans!
Interested in getting your own thought leader profile? Get Started Today.
Paige Roberts
Independent Data, AI, and Analytics Industry Analyst at Strigid Insight
Hamilton, United States
Paige Roberts (@RobertsPaige) has worked as an engineer, trainer, support technician, technical writer, marketer, product manager, and a consultant in the last 25 years. She contributed to "97 Things Every Data Engineer Should Know" and co-wrote "Accelerate Machine Learning with a Unified Analytics Architecture" and "Up and Running with Aerospike" all published by O'Reilly Media. She's spoken at conferences like Big Data London, Strata, DBTA Data Summit, Data Connect, ODSC, and Big Data Conference Europe. She's worked for companies like Data Junction, Pervasive, Bloor Group, Hortonworks, Syncsort, Vertica, and GridGain. Now, she promotes understanding of realtime distributed data processing, high scale data engineering architecture, and how the analytics revolution is changing the world.
Available For: Advising, Authoring, Consulting, Speaking Travels From: Texas
Speaking Topics: AI, Analytics, Machine Learning, Data Architecture, Event Stream Processing, Data Pipelines, Data Management
Speaking Fee
$5,000 (In-Person), $2,000 (Virtual)
Paige Roberts
Points
Academic
31
Author
219
Influencer
85
Speaker
85
Entrepreneur
0
Total
420
Points based upon Thinkers360 patent-pending algorithm.
Where will Agentic AI advance the most in the next 1-3 years
March 23, 2026
Unifying Analytics - in person Big Data London
March 23, 2026
AI, Human Connection, Guard Rails and Ethics
March 23, 2026
Featured Topics
Data Architecture - optimizing enterprise data architecture for analytics and AI speed at scale
IASA certified in data architecture fundamentals - Strategies for reducing data analysis and AI latency, for dealing with data in motion and data at rest simultaneously, and for getting real business value from advanced analytics.
Seeing past the fog of data management and AI hype and myths
The hype machine in the data management, analytics, and AI space works overtime to make everything seem like you absolutely must have it, or your organization will be left behind! You're failing! Figuring out what new technologies and strategies have real merit and which are just smoke and mirrors can be overwhelming. Having been behind the curtain, I can help guide organizations to the real value behind the smokescreen.
Product Marketing Speaking Engagements - Conference Presentations, Training Sessions, Strategy, and Advice
The biggest challenge nearly every data management and analytics product faces is awareness. If people don't know about your product, you can't sell it. I'm an expert at finding the value of your specific technology to the market, and framing that in public presentations so potential customers know your technology exists, know what your technology does, and know why it would benefit them to have it.
Company Information
Strigid Insight
Independent Data, AI, and Analytics Industry Analyst
GridGain Developer Essentials: Apache Ignite
GridGain
November 26, 2024
The owner of this badge attended an Apache Ignite Essentials training session for developers and architects and learned how to increase the speed and scale of applications by leveraging Apache Ignite's essential capabilities (data partitioning, affinity co-location, and co-located processing)
Earners of the IASA CITA-Foundation badge have demonstrated the ability to interact with Architects based on an awareness of the IT Architecture Body of Knowledge, with an understanding across the five pillars of Architecture.
We drive the expansion of women in architecture roles towards an equal balance and enable women to thrive and contribute with impact.Through the increased and equal contributions of women in architecture, we will leverage our own diversity as the way forward to build unity and harness the full power of architecture to make a difference for our organizations, societies, and world.
AI Governance Guide: Building Trust into Your Platform
Anaconda
December 19, 2025
Enterprise AI adoption is being held back, not by lack of innovation, but by lack of trust. While organizations rush to implement AI, they’re discovering that ungoverned open-source software creates heightened security and compliance risks. The companies best positioned to succeed with AI are those that solve AI governance first—turning it from a blocker into an accelerator of AI innovation. This guide explores the fundamentals of a solid AI governance platform, and how to have a secure, well-governed AI ecosystem.
Architecting a Modern Data Stack for AI Agents
Enterprise AI World
October 03, 2025
Even if you’ve got a brand-new business model based specifically on the capabilities of a language-centered AI agent, you still have to deal with time-honored challenges such as disparate and scattered data, slow response, finding necessary information, and trusting that information.
On top of these historical data management issues, you now have even more challenges, such as context caching, prompt template storage and reuse, and how to use reflection and other agentic techniques for better output.
Streaming vs Batch, Lakehouse, and Data Architectures of the Future
Medium
August 14, 2025
My old friend Jesse Anderson has a video podcast series called Unapologetically Technical. He interviews prominent folks in the data management space, discussing their careers. Then the guest interviewee dives into a technical topic on a whiteboard. The latest guest on Unapologetically Technical was ME! And I know this is shocking to all who know me, but the technical subject I dove into was data architectures, past, present, and future.
https://medium.com/@paigeonthewing/gen-ai-writing-theft-and-llms-eating-their-own-tails-7789a16a04d5
Medium
May 27, 2025
Not using AI to generate my content doesn't make me "anti-AI." You can't spell Paige without "AI." Generative AI and the Large Language Models (LLM) behind it, are powerful, with a lot of great uses. Still, as a multi-decade experienced writer, and data management industry pundit, I have no need to use generative AI to write my content for me. But, the opposite isn't true. To train the next generation of more capable gen AI models, apparently, Meta apparently needs to train them on my copyrighted content.
Gen AI, Writing, Theft, and LLMs Eating Their Own Tails
Medium
May 27, 2025
The other day, I posted a rant on LinkedIn about someone referring to me as “anti-AI” because I don’t use Gen AI to create my content. For the record, I am the opposite of anti-AI. I am doing my best to help people make AI successful in their organizations by feeding AI more and better data faster. I’ve made my living for years talking about better data architectures for AI. Fred Lardaro commented on that rant
Agentic AI is the New Internet
Medium
October 17, 2024
It’s obvious that agentic AI is the next logical step in the AI evolution.
Agentic AI is the hottest new buzzword. It takes the one shot — prompt it and get a response — of generative AI, and puts that as a single step in a more complex workflow which at the end DOES something. The steps in the workflow are things like planning, revision, checking or testing, using tools to do more things like searching the net for more information, using multiple AI agents to do different parts of a job so it can be done in parallel. There are a lot of concepts in Agentic AI designed to make Gen AI more useful, more like a complete application.
APTs are Everywhere — Why my piddly site keeps getting Cyrillic junk comments and attacks from Singapore
Medium
September 20, 2024
Anyone with their resume on line, a blog, or any kind of personal website is a target of nation-state sponsored advanced persistent threat attacks. An old friend, Eric Kavanagh, recently lamented on LinkedIn that his analytics showed multiple attacks on his data management journalism site from Singapore and Bulgaria.
When Linear Scaling is Too Slow—Build for Fast Hardware
Medium
February 09, 2024
The main question the talk I gave at Data Day Texas 2024 sought to answer was: What strategies do cutting edge database technologies use to get eye-popping performance at petabyte scale?
All of the strategies I’ve talked about in previous posts have been spinning disk focused, mainly strategies that Vertica, an analytical database built for commodity hardware uses. Anything that takes longer than a microsecond for many use cases is too slow. The strategies I discussed earlier involve optimizing spinning disk I/O, but in the end, spinning disk can only go so fast. But Aerospike needed a way to take transactional databases to the next level and flash drives held the key. So, they built an entire database on top of this new SSD technology.
Build your software to run on the fastest available hardware.
When Linear Scaling is Too Slow - Compress Your Data
Medium
February 08, 2024
The main question the talk I did at Data Day Texas 2024 sought to answer was: What strategies do cutting edge database technologies use to get eye-popping performance at petabyte scale?
The strategy that really takes an application past linear scaling and into reverse linear scaling is one that Vertica (or whatever OpenText is going to call it now) has mastered — aggressive data compression.
Data compression can take your application way beyond linear scaling to reverse linear scaling.
When Linear Scaling is Too Slow - Share Nothing
Medium
February 07, 2024
The main question the talk sought to answer overall was: What strategies do cutting edge database technologies use to get eye-popping performance at petabyte scale?
The next strategy I recommended at Data Day when designing software for high performance at extreme scale is a shared nothing architecture. Both Vertica and Aerospike have it, and frankly, any distributed data processing system built since Hadoop should have this foundational strategy. They don’t all have it, but they should. Hadoop taught us that edge, master, leader, whatever you want to call it nodes were not helpful. I have been surpised over the years to find otherwise smart distributed data processing systems like Presto still making that mistake.
One lesson learned from the last 15 years was that differentiated nodes are bottlenecks that can limit scaling.
When Linear Scaling is Too Slow: Isolate Your Workloads
Medium
February 06, 2024
I used knowledge from many years in this industry, including 5 years working at Vertica. Plus, a fair amount of knowledge gained from working on an O’Reilly book for Aerospike alongside the architect, and a lead database engineer from The TradeDesk, a company that uses both Vertica and Aerospike.
The main question the talk sought to answer was: What strategies do cutting edge database technologies use to get eye-popping performance at petabyte scale?
The first good strategy I presented was workload isolation.
When Linear Scaling is Too Slow — The last strategy you should use.
Medium
February 05, 2024
How do you design for data processing performance at extreme scale?
Sometimes linear scaling just isn’t good enough. What strategies do cutting-edge technologies use to get eye-popping performance in petabyte scale databases?
What scaling strategy that everyone thinks of first, is actually the last strategy you should use?
What’s New in OpenText Analytics Database
OpenText
January 17, 2024
The newest version of OpenText Vertica 24.1 (representing the first quarter of 2024) is all about saving operating costs while boosting value. The star in this release is an extraordinary new capability – workload routing. It makes each job more efficient and performant, decreasing spending and energy usage for each type of work by directing it to ideal hardware automatically. Read on to learn more or request a demo of the OpenText Analytics & AI platform today.
Busting Cloud Myths and Avoiding Cloud Pitfalls
Cloud Computing Magazine
September 22, 2023
Cloud computing is one of the greatest IT revolutions of our time, but many of the things that “everyone knows” about cloud are actually myths. Let’s explore the most common concepts surrounding cloud computing to determine which have been proven out by time, and which myths have been busted.
AIOps: 4 Common Challenges and 3 Key Considerations for Using AI in IT Operations
CDO Magazine
August 29, 2023
AIOps projects hold tremendous potential in IT operations management. However, only about half of all AI projects see production. Author Paige Roberts sheds light on the critical factors that add to that difficulty along with the important considerations that can help.
What Does Real-time Really Mean In Data Analytics?
InsideBigData
August 25, 2023
Demystifying Real-time Data Analytics: Understanding Definitions, Categories, and Strategies for Unlocking Value in the Data-driven Era
Is an analytical response within 300 milliseconds on data generated yesterday considered realtime? In today’s fast-paced digital landscape the concept of realtime data analysis has become increasingly prevalent and essential to business success. Yet, there’s a lot of confusion about what “realtime” really means.
Understanding the definitions when discussing real-time data analysis is crucial to unlocking the potential of realtime analytics to propel business growth in this data-driven era.
One refinement I propose is the need to differentiate between end-to-end realtime data analysis and fast response from already prepared data.
Consider Performance, Growth & Budget When Buying Data Analytics
DevOps.com
May 09, 2023
So, your business needs to invest in data analytics technology to improve efficiencies, competitive advantage or business outcomes. There are a ton of things to consider, but underlying each decision are three driving factors:
Performance – The need to meet service level agreements.
Growth – The need to accommodate success, as well as deal with inevitable industry changes.
Budget – The need to do both of the above while keeping costs low enough to not erode the profit gain from analytics.
These three forces underpin nearly every technology selection decision, but what frequently isn’t noticed is how much these three drivers interact.
Save the Planet with Better Software — Vertica Analytics for ESG
Medium
April 21, 2023
Whether you call it Green IT or ESG (Environmental, Social, Governance), every responsible company in every industry is striving to change the way they do things to do their part to save this planet. The compute industry has been focusing on this concern for a long time. Co-location data centers have strived for years to go from giant energy hogs to zero carbon impact.
A lot of people don’t think that software like Vertica, now a part of OpenText Analytics and AI, has any contribution to make. But they’d be wrong. I’m going to make a wild claim. And then I’m going to back it up with some facts.
If every company that does big data analytics now switched to Vertica, we could cut energy usage for analytics globally in half.
Is Cloud Repatriation a Big Lie Server Vendors Are Shilling?
Spiceworks
April 03, 2023
Cloud repatriation spotlights the need to avoid letting hype determine your analytics strategy. Paige Roberts, Open Source relations manager at Vertica, gets to the bottom of what reverse cloud migration is all about and the purpose it may serve.
Why Can’t We Have AI-Driven Database Design?
Medium
February 21, 2023
One of the most time-consuming, expensive, expertise-intensive aspects of getting a new analytics database up and running is data modeling and overall database design. There’s this huge, months long project that involves interviewing all the folks wanting to do analytics — trying to understand their requirements, and then understand the data in relation to those requirements. How much data do they need to analyze, how fast is that data coming in, what kind of analyses do they do on it? Will they need to power a dashboard, run an application, analyze locations, deal with the avalanche of IoT data? Usage patterns? Constraints? Primary keys? Naming conventions? Indexes?
So many questions, and so much time and effort by smart people to determine how a database’s tables, indexes, etc. should be set up.
Five Reasons Why In-Database Machine Learning Makes Sense
IASA Architecture and Governance Magazine
February 12, 2023
Of the few ML projects that make it to production, most take 3 months to a year. Organizations don’t receive benefits from data science until it’s in production. Does that mean adding another technology to bloated stacks? Vertica’s presentation is about getting machine learning into production faster with something nearly every company already has: a good analytics database.
New O’Reilly Book: Accelerate Machine Learning with a Unified Analytics Architecture
Medium
February 16, 2022
Between 40 and 60% of machine learning projects fail, most at the point in the workflow between proof of concept and production. One day, it may be as easy for an organization to put an ML model into production as it is to put a new visualization in a BI report. The right data architecture design can be the key.
What’s the Difference Between a Data Lakehouse and a Unified Analytics Platform?
Architecture and Governance Magazine
November 12, 2021
I’ve been doing a bunch of speeches at various conferences on the merging of the data warehouse and data lake into a single unified analytics platform. I inevitably get one question, “How is this different from a lakehouse?” There are two answers, a short one that’s glib and easy, and a longer one that really dives into things. Short answer, “They’re extremely similar architectural concepts.” The rest of this article is the long answer.
It’s a Trap! — Cloud Financial Incentive for Badly Optimized Analytics Software
Medium
October 15, 2021
For all the years I’ve been working with data management and analytics software, there’s always been a powerful motivation to be as efficient as possible. The smarter your software is about using available computer resources — hardware, disk, memory, CPU… — the bigger your edge over the competition. The happier your customers are, the more money your company makes. The financial incentive to be more and more performant on less and less compute has always been enough to motivate endless tweaks to eke out just a little more speed, or figure out ways to do just a little bit more with the same hardware.
This benefits the customer, who constantly gets better and better software.
Then the cloud came along, and things seemed the same, for the most part. You could no longer say “hardware” to mean the storage and compute infrastructure, but I still assumed everyone in the data management and analytics software industry was in that same race, to be more and more performant on less and less compute “infrastructure.”
What Do People Mean by “Cloud-Native?”
Medium
July 28, 2021
Cloud-native is an important buzz word in the data storage and analytics space these days. The way we hear folks use it to advertise their software, it sounds like it must be something wonderful, a data analytics superhighway. But it seems like the meaning shifts depending on who is saying it. It’s a big red flag to me when a phrase means whatever people want it to mean at that moment, mainly to convince you that their software is superior to other software in some nebulous, undefined way, so you’ll buy it. The next time you hear someone using cloud-native in a sentence, consider what they might actually mean.
Container Boom: Should Databases Be Containerized?
Rtinsights
June 11, 2021
Several years back, the application technology industry had this concept of breaking big applications up into smaller independent components, microservices, and deploying each in its own container. The container idea has some pretty cool advantages it turns out:
Moving to real-time stream processing-some basics
Linkedin
September 03, 2025
Welcome to Streaming Intelligence News, the newsletter designed to provide you with the latest information in streaming and graph data processing. This edition discusses streaming data processing, data pipelines, and how they fit together in an analytics architecture or real-time application architecture.
Early Release:
If you're a developer looking to build a distributed, resilient, scalable, high-performance application, you may be evaluating distributed SQL and NoSQL solutions. Perhaps you're considering the Aerospike database.
This practical book shows developers, architects, and engineers how to get the highly scalable and extremely low-latency Aerospike database up and running. You will learn how to power your globally distributed applications and take advantage of Aerospike's hybrid memory architecture with the real-time performance of in-memory plus dependable persistence. After reading this book, you'll be able to build applications that can process up to tens of millions of transactions per second for millions of concurrent users on any scale of data.
This practical guide provides:
Step-by-step instructions on installing and connecting to Aerospike
A clear explanation of the programming models available
All the advice you need to develop your Aerospike application
Coverage of issues such as administration, connectors, consistency, and security
Code examples and tutorials to get you up and running quickly
And more
Accelerate Machine Learning with a Unified Analytics Architecture
O'Reilly
February 12, 2022
Unification of data warehouse and data lake architectures into something new - whether you call it a unified analytics architecture, a data lakehouse, or something else - is a trend that nearly every company seems to be moving toward over the last five years. This new architecture combined with in place machine learning on whole data sets is revolutionizing how data analysis at scale gets done. Read this book to learn how you can get machine learning models into production in minutes, not months.
97 Things Every Data Engineer Should Know
O'Reilly
July 06, 2021
From the Preface
Data engineering as a distinct role is relatively new, but the responsibilities have existed for decades. Broadly speaking, a data engineer makes data available for use in analytics, machine learning, business intelligence, etc. The introduction of big data technologies, data science, distributed computing, and the cloud have all contributed to making the work of the data engineer more necessary, more complex, and (paradoxically) more possible. It is an impossible task to write a single book that encompasses everything that you will need to know to be effective as a data engineer, but there are still a number of core principles that will help you in your journey.
This book is a collection of advice from a wide range of individuals who have learned valuable lessons about working with data the hard way.
To save you the work of making their same mistakes, we have collected their advice to give you a set of building blocks that can be used to lay your own foundation for a successful career in data engineering. In these pages you will find career tips for working in data teams, engineering advice for how to think about your tools, and fundamental principles of distributed systems.
There are many paths into data engineering, and no two people will use the same set of tools, but we hope that you will find the inspiration that will guide you on your journey. So regardless of whether this is your first step on the road, or you have been walking it for years we wish you the best of luck in your adventures.
Strategies to Modernize Your Data & Analytics Architecture
Camp IT Education
June 30, 2020
Data warehouses were analytics workhorses for decades, but couldn’t handle modern data volumes, types, and advanced analyses like machine learning. Big Hadoop promises about the data lake didn’t pan out. Learn how successful past, current and future architectures combine strengths of data lakes and data warehouses to make something better than both.
AI, Human Connection, Guardrails, and Ethics
It's About Data - Tony Baer and Matt Housley
March 19, 2026
Interview on AI governance, ethical considerations, current wrongs AI is doing which are entered in the incidentdatabase.ai, and some ideas on how to put guardrails around agents.
Unapologetically Technical Paige Roberts - Consultant Ep.23
Unapologetically Technical - Jesse Anderson
August 12, 2025
In this episode of Unapologetically Technical, Jesse interviews Paige Roberts, a 30-year veteran of the data industry who describes herself as an author, presenter, and "data nerd." Paige shares her multi-path career journey, revealing how she went from teaching deaf students and learning programming on the fly to becoming a programmer, tech writer, consultant, marketing manager, and data architect, often wearing multiple hats at once.
Faster Time-to-Value with In-Database Machine Learning
https://techhq.com/
February 03, 2022
We spoke recently to Paige Roberts, the Open Source Relations Manager at Vertica, about how organizations solve some of the problems of getting advanced analytics projects into production, reducing the time taken to have ML models start producing practical and useful results for businesses using in-database machine learning.
Architecting for Speed & Scale - Get Consistency & Real-Time Latency With a DIH
DBTA Data Summit
May 15, 2025
Systems of record (SORs) are scattered across large enterprises, each individually fit for a specific purpose. If you want to use that data to digitally transform business, you need to access all your data to drive applications and analytics. A data integration hub (DIH) isn’t another database. It’s an architectural concept that fits in between SORs and front-end applications. Necessary data is provided at real-time speed, and long-term data is reconciled across sources and persisted dependably, regardless of source format. Come to this talk to see some real-world implementations in financial, telecom, transportation, and logistics industries of a DIH. Learn the concepts, tips, tricks, and gotchas.
Unlocking the Power of Real-Time Data and Analytics
DBTA
November 14, 2024
DBTA round table webinar with multiple presenters. Each did a short presentation, then a panel discussion on real-time data processing challenges and important tips and tricks.
Streaming Graph Processing on Categorical Data Enables Real-time Risk Calculation
Women in Analytics - Data Connect 2024
July 12, 2024
Failures like the Silicon Valley Bank in 2023 is the extreme result of not accurately calculating risk in a timely manner. Nearly every financial institution has a focus on minimizing risk, but the way we calculate that inherently requires close analysis of categorical data and relationships. Yet the majority of our algorithms only work on static, numeric data. That means persisting the data, converting it using something like one hot encoding into numerical data that is bloated, sparse, and slow to analyze, then after analysis, often having to convert again to figure out the original categories. This is painfully slow, with the state of the art being measured in hours. If we could shift that analysis left, process the original categorical data as it streams in, without modification, that could cut mean time to insight down to seconds, and possibly save financial institutions some large dollar signs. That could also enable many other options, such as using graph NLP on flowing data, finding novel behavior, detecting anomalies such as cyber-attacks before they affect systems. The speed of an in-line data processing engine like Flink or KsqlDb combined with graph algorithms and categorical analysis is uniquely powerful. Come learn about a new open source streaming intelligence system that changes the game for risk analysis and other fast categorical data processing.
Get Better Analytics by Putting Less Data in Your Database
DBTA Data Summit 2024
May 08, 2024
A recent survey showed that 67% of companies had their software budgets cut during 2023. SaaS databases are easy to use and powerful, but they put a strain on budgets. Still, no one can afford to skimp on smart data analytics. How do you get more analytics out of your SaaS data warehouse/lakehouse, without spending more money? Treat incoming data streams as a graph. Relationships and categories of data can immediately be seen and acted upon. Duplicate entities can be resolved. Key pattern signals in noisy data streams can be pinpointed and the noise that you don’t need tossed out. By putting only relevant and clean data into analytical repositories, tons of useless data never have to be stored in pay-per-use systems, vastly reducing costs. You get smarter answers on clean, pre-filtered data in real time.
Shift Difficult Problems Left with Graph Analysis on Streaming Data
The Bloor Group - Inside Analysis
April 29, 2024
Host @eric_kavanagh will interview former Gartner Analyst Sanjeev Mohan, ExxonMobil Senior Technical Engineer H. Alexander Huskey, and Paige Roberts, Director of Product Innovation at thatDot, who will explain the value of shifting tough analysis to earlier in the process. She'll discuss how a graph analysis of flowing data can benefit your business.
Key business applications include:
• Real-time Risk analysis and Fraud Detection: Uncover intricate fraudulent activity patterns across transactions, user behaviors, and device data that traditional rules-based systems would miss.
• Cybersecurity and APT Detection: Identify anomalous patterns in network traffic, user logins and device logs to proactively prevent security breaches with no time window limitations.
• IoT Edge Smart Filtering: Monitor sensor data streams from industrial and other devices, understand which data is useful so you don’t flood downstream systems, and act immediately when problems arise.
When linear scaling is too slow – strategies for high scale data processing
Data Day Texas
January 27, 2024
How does the TradeDesk handle 10 million ad auctions per second and generate 40 thousand reports in less than 6 hours on 15 petabytes of data? If you want to crunch all the data to train an LLM AI model, or handle real-time machine scale IoT problems for AIOps, or juggle millions of transactions per second, linear scaling is far too slow.
Is the answer a 1000-node database with a ton of memory on every node? If it was, companies like the TradeDesk would have to declare bankruptcy. Throwing more nodes or serverless executors at the problem either on cloud or on-premises is neither the only, nor even a good solution. You will rapidly hit both performance and cost limitations, providing diminishing returns.
So, how do extreme high scale databases keep up? What strategies in both open source and proprietary data processing systems leave linear scaling in the dust, without eating up corporate ROI? In this talk, you’ll learn some of the strategies that provide affordable reverse linear scaling for multiple modern databases, and which direction the future of data processing is going.
Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
DBTA
May 10, 2023
There are a lot of advantages to moving to the cloud. But the more various organizations move to the cloud, the more we see them tripping over hidden land mines like out-of-control costs, platform lock-in that restricts future options, regulations that restrict data location, etc. How can a company shift data analysis workloads into the cloud, while minimizing their exposure to those risks?
In this session, you will learn how to:
• transition to the cloud, while keeping some workloads on prem,
• move to multiple clouds without hopelessly complicating analytics
• maintain high throughput and low latency in cloud analytics
• keep platform options for the future open
Use AIOps to Improve Uptime and Reduce Mean Time to Repair
IWCE
March 27, 2023
Hardware breaks. While a lot of industries talk about going to the cloud – aka someone else’s hardware – to solve uptime issues, this doesn’t work so well when you ARE someone’s hardware provider. Whether you’re a telecom company with towers and networks, a computer infrastructure company, an energy utility, a manufacturing company, or even a car company – anyone who provides solid metal hardware needs to make sure it keeps running.
AIOps is the smart application of advanced analytics including machine learning to monitor, and in many cases fix IT related problems before the end user is even aware of them. A good example is HPE Infosight, that has embedded analysis capability in every computer they sell. For them, it improves the productivity of support technicians by reducing support calls as much as 80% or more, and boosting customer satisfaction by increasing uptime proportionately. A wide variety of other industries are getting similar benefits by embedding the ability to analyze IoT data.
Telecom is another industry with a constant need to monitor traffic, automatically identify overloaded areas, and reroute calls to prevent outages or dropped calls. Where should your next tower go? How can the flood of 5G data be captured, managed, and put to use, without overloading staff or technology?
In every industry, the key question is: How can I find and fix issues before customers are aware of the problem, or at least vastly reduce the mean time to repair those issues that do occur? AIOps holds the key. Harness the flood of IoT data to catch and prevent incidents before they happen, or fix them as soon as possible after they happen.
This sounds amazing as a concept, but how do companies implement this? What is involved? What gotchas hide in the details? With examples from leaders in multiple industries, this presentation will help you learn:
• What is AIOps and what can you expect from a solid implementation
• Benefits AIOps provides in various use cases: predictive maintenance, performance optimization, network bottleneck identification and remediation, MTTR reduction, etc.
• Example implementations - problems you are likely to run into, requirements to make it work, tradeoffs you need to consider, etc.
Build analytics for performance and growth on a budget
Data Day Texas
January 28, 2023
When building or changing an enterprise analytics architecture, there are a lot of things to consider–Cloud or on-prem, hybrid or multi-cloud, this cloud or that cloud, containerized, build tech, buy tech, use the skills in house, train new skills, etc. While balancing those decisions, there are a lot of considerations, but the main three are performance, costs, and planning for the future including future growth in analytics demand.
In this session, get some solid data on how to build a data analytics architecture for performance and rapid growth, without breaking the budget, by focusing on what is important and looking at some examples of architectures at companies that are tackling some of the toughest analytics use cases. Learn from others’ mistakes and successes. Learn how real companies like the Index Exchange, Simpli.fi, and the Tradedesk analyze data up to petabyte ranges, track millions of realtime actions, generate 10’s of thousands of reports a day, keep thousands of machine learning models in production and performing, and still keep budgets under control.
Get Projects into Production Faster with In-DB ML
Big Data Europe
November 24, 2022
MLOps has rocketed to prominence based on one, clear problem: many machine learning projects never make it into production. According to a couple of recent surveys, between 30 and 60% of even the small percentage of projects that do make it take 3 months to a year to get put to work. Since data science is a cost center for organizations until those models are deployed, the need to shorten, organize, and streamline the process from ideation to production is essential.
Data science is not simply for the broadening of human knowledge, data science teams get paid to find ways to shave costs and boost revenues. That can mean preventative maintenance that keeps machines on line, churn reduction, customer experience improvements, targeted marketing that earns and keeps good customers, fraud prevention or cybersecurity that keeps assets safe and prevents loss, or AIOps that optimizes IT to get maximum hardware uptime for minimum costs.
To get those benefits, do you need to add yet another piece of technology to already bloated stacks? There may be a way for organizations to get machine learning into production faster with something nearly every company already has: a good analytics database.
Learn how to:
• Enable data science teams to use their preferred tools – Python, R, Jupyter – on multi-terabyte data sets
• Provide dozens of data types and formats at high scale to data science teams, without duplicating data pipeline efforts
• Make new machine learning projects just as straightforward as enabling BI teams to create a new dashboard
• Get machine learning projects from finished model to production money-maker in minutes, not months
Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
Big Data and AI Toronto
October 06, 2022
There are a lot of advantages to moving to the cloud. But the more various organizations move to the cloud, the more we see them tripping over hidden land mines like out-of-control costs, platform lock-in that restricts future options, regulations that restrict data location, etc. How can a company shift data analysis workloads into the cloud, while minimizing their exposure to those risks?
In this session, you will learn how to:
• transition to the cloud, while keeping some workloads on prem,
• move to multiple clouds without hopelessly complicating analytics
• maintain high throughput and low latency in cloud analytics
• keep platform options for the future open
Achieving Unified Analytics
DBTA Data Summit
May 17, 2022
The data warehouse has been an analytics workhorse for decades for business intelligence teams. But unprecedented volumes and new types of data, plus the need for advanced analyses, brought on the age of the data lake. Now, many companies have a data lake for data science, a data warehouse for BI, or a mishmash of both—possibly combined with a mandate to go to the cloud. Find out how technical and spiritual unification of the two camps can have a powerful impact on the effectiveness of analytics for the business overall.
Data Con LA 2021 - In-Database Machine Learning with Jupyter
DataCon LA
September 29, 2021
Jupyter with Python code is a productive way to prepare models, but putting machine learning models into production at scale may require re-building the entire workflow. Using the same interactive tools, but letting a distributed database do the work could get ML models into production in minutes, not months.
Making Production Data Accessible for Data Science at Scale
Big Data London
September 22, 2021
The data warehouse has been an analytics workhorse for decades for business intelligence teams. Unprecedented volumes of data, new types of data, and the need for advanced analyses like machine learning brought on the age of the data lake. Now, many companies have a data lake for data science, a data warehouse for BI, or a mishmash of both, possibly combined with a mandate to go to the cloud. The end result can be a sprawling mess, a lot of duplicated effort, a lot of missed opportunities, a lot of projects that never made it into production, and a lot of financial investment without return. Technical and spiritual unification of the two opposed camps can make a powerful impact on the effectiveness of analytics for the business overall.
- Look at successful data architectures from companies like Philips, The TradeDesk, Climate Corporation, …
- Learn to eliminate duplication of effort between data science and BI data engineering teams
- See a variety of ways companies are getting AI and ML projects into production where they have real impact, without bogging down essential BI
- Study analytics architectures that work, why and how they work, and where they’re going from here
Python + MPP Database = Large Scale AI/ML Projects in Production Faster
ODSC East
April 28, 2021
Getting Python data science work into large scale production at companies like Uber, Twitter or Etsy requires a whole new level of data engineering. Economies of scale, concurrency, data manipulation and performance are the bread and butter of MPP analytics databases. Learn how to take advantage of MPP scalability and performance to get your Python work into production where it can make an impact.
Unifying Analytics - Production Analytics Architecture Evolution
Big Data Virtual Masterclass
July 22, 2020
The data warehouse has been an analytics workhorse for decades. Unprecedented volumes of data, new types of data, and the need for advanced analyses like machine learning brought on the age of the data lake. But Hadoop by itself doesn’t really live up to the hype. Now, many companies have a data lake, a data warehouse, or a mishmash of both, possibly combined with a mandate to go to the cloud. The end result can be a sprawling mess, a lot of duplicated effort, a lot of missed opportunities, a lot of projects that never made it into production, and a lot of financial investment without return.
Technical and spiritual unification of the two opposed camps can make a powerful impact on the effectiveness of analytics for the business overall.
Over time, different organizations with massive IoT workloads have found practical ways to bridge the artificial gap between these two data management strategies. Look under the hood at how companies have gotten IoT ML projects working, and how their data architectures have changed over time. Learn about new architectures that successfully supply the needs of both business analysts and data scientists. Get a peek at the future. In this area, no one likes surprises.
- Look at successful data architectures from companies like Philips, Anritsu, Uber, …
- Learn to eliminate duplication of effort between data science and BI data engineering teams
- Avoid some of the traps that have caused so many big data analytics implementations to fail
- Get AI and ML projects into production where they have real impact, without bogging down essential BI
- Study analytics architectures that work, why and how they work, and where they’re going from here
Unifying Analytics: Architecting Production IOT Analytics
Pulsar Summit
January 24, 2020
Analyzing Internet of Things data has broad applications in a variety of industries from smart buildings to smart farming, from network optimization for telecoms to preventative maintenance on expensive medical machines or factory robots. When you look at technology and data engineering choices, even in companies with wildly different use cases and requirements, you see something surprising: Successful production IoT architectures show a remarkable number of similarities.
Join us as we drill into the data architectures in a selection of companies like Philips, Anritsu, and Optimal+. Each company, regardless of industry or use case, has one thing in common: highly successful IoT analytics programs in large scale enterprise production deployments.
By comparing the architectures of these companies, you’ll see the commonalities, and gain a deep understanding of why certain architectural choices make sense in a variety of IoT applications.
Unapologetically Technical
YouTube
August 13, 2025
My old friend Jesse Anderson has a video podcast series called Unapologetically Technical. He interviews prominent folks in the data management space, discussing their careers. Then the guest interviewee dives into a technical topic on a whiteboard. The latest guest on Unapologetically Technical was ME! And I know this is shocking to all who know me, but the technical subject I dove into was data architectures, past, present, and future.
InsightJam - Where Will Agentic AI Advance the Most in the Next 1-3 Years?
Solutions Review
March 31, 2025
Will agentic AI replace traditional enterprise applications?
What role will humans play in future AI agent-driven systems?
Our industry experts explore the near-future evolution of agentic AI, emphasizing its shift from handling tasks to reshaping entire applications and workflows. The panel discusses how AI will create personalized interfaces that respond to natural language rather than requiring complex button sequences. They highlight AI's emerging role as an orchestration layer working alongside existing systems while enabling digital twins that handle routine interactions on our behalf.
The Race to Unified Analytics: Next-Gen Data Platforms and Architectures
DBTA
July 13, 2023
Despite ongoing investment in cloud platforms and analytics tools, many companies are still struggling with truly unlocking the business value of all their data. While the ways that users want and need to work with data continue to evolve, the increasing complexity of data and analytics systems and proliferation of data silos often pose significant hurdles. This is especially true when data is managed across a patchwork of legacy systems and new technologies adopted tactically without full consideration of broader data management imperatives and future needs. Ultimately, organizations want to empower their users with fast, easy access to actionable, reliable information and insights.
Unlock the Value in Data: Rise of Hybrid Cloud, Multi-Cloud Platforms
Vertica
April 21, 2022
Being limited to analyzing data on-premises is a known problem. But analytics limited to cloud, or just a single cloud vendor, can also reduce the return on your data investment. To unlock the value of data, companies must embrace the reality of a hybrid world.
In this webcast, we’ll dive into solid Eckerson Group research on how companies across industries are getting their arms around data in multiple clouds and on-prem systems. ThinkData Works is an example of a successful technology company at the center of this important trend. We invite you to learn how ThinkData Works is helping customers pull in new sources and manage external data at scale to reduce risk, boost efficiency, and drive innovation.
Cloud Without Compromises: Crucial Analytical Data Platform Requirements
Vertica
March 15, 2022
Most organizations are moving their analytical data platforms – whether based on data warehouses, data lakes, or both — into the cloud. But how do you choose the right platform to fit your organizational realities, your technology strategy and direction, and important product requirements? What are the compromises in choosing a platform that is only available as a cloud service or only available in one cloud? And what are the capabilities you should look for beyond support for business intelligence and analytics, particularly when it comes to supporting machine learning and data science?
Join Doug Henschen, VP and principal analyst at Constellation Research, and author of “What to Consider When Choosing a Cloud-Centric Analytical Data Platform,” for this informative web event on March 10 at 8 am PT/11 am ET. He’ll be joined by Paige Roberts, Open Source Relations Manager at Vertica, and by Bert Corderman, Senior Manager of Engineering at The Trade Desk.
Find the Balance Between MPP Databases and Spark for Analytical Processing
Vertica
August 25, 2021
Both Apache Spark and massively parallel processing (MPP) databases are designed for the demands of analytical workloads. Each has strengths related to the full data science workflow, from consolidating data from many siloes, to deploying and managing machine learning models. Understanding the power of each technology, and the cost and performance trade-offs between them can help you optimize your analytics architecture to get the best of both. Learn when using Spark accelerates data processing, and when it spreads far beyond what you want to maintain. Learn when an MPP database can provide blazing fast analytics, and when it can fail to meet your needs. Most of all, learn how these two powerful technologies can combine to create a perfect balance of power, cost, and performance.
Thought Leadership: Modernize Data Warehousing – Beyond Performance
Vertica
March 15, 2021
Configuration, management, tuning and other tasks can take away from valuable time spent on business analytics. If a platform leads to coding workarounds, non-intuitive implementations and other problems, it can make a big impact on long-term resource usage and cost. A lot of enterprise analytics platform evaluations focus on query price-performance to the exclusion of other features that can have a huge impact on business value, and can cause major headaches if you don’t take them into consideration.
In this webinar, we’ll go beyond price-performance, and focus on everything else needed to modernize your data warehouse.
Natural Language Processing Augmented Analytics
Vertica
November 17, 2020
The goal of data analytics, whether business intelligence or advanced analytics like machine learning has always been to guide organizations with solid data, rather than feelings. While every company strives to be data-driven, this requires making analytics accessible to more people. What could be more accessible than asking your data a question in your own language? Tune in to learn about natural language processing, the challenges and benefits of this exciting technology, and how it can democratize data analytics, and bring business results to the next level.
As agentic AI workflows become more capable of writing code, testing it, tweaking it, and producing nearly complete applications based on the specifications, software engineering will be radically accelerated, and democratized to some extent. Impact and risk factors are that a lot of organizations will fire engineers, thinking AI can now replace them. This is a seriously bad idea. In the end, they'll either end up hiring them back for higher salaries, or see a major drop in code quality. We're already seeing that rehire happening. Eventually, this specs as code technique could make good software a thing that many more people can create or modify. But the AI itself IS code. Good developers will be needed to make it work, and agentic workflows will become an extremely valuable area of expertise.
Content Targeting, Management, and Creation for Data Management, Analytics, and AI
Location: Middle of Nowhere, TX Fees: $200 - $300/hour, by the word, or f
Service Type: Service Offered
Do you need white papers, web content, someone to manage, edit, and contribute to your company blog? I have over 25 years experience in the data management, analytics, and AI space. My specialties are matching your software's strengths to the market's needs, and creating content that is perfectly targeted for the audience you want to reach.
Location: Columbus, Ohio Date : July 10, 2024 - July 12, 2024 Organizer: Women in Analytics
Failures like the Silicon Valley Bank in 2023 is the extreme result of not accurately calculating risk in a timely manner. Nearly every financial institution has a focus on minimizing risk, but the way we calculate that inherently requires close analysis of categorical data and relationships. Yet the majority of our algorithms only work on static, numeric data. That means persisting the data, converting it using something like one hot encoding into numerical data that is bloated, sparse, and slow to analyze, then after analysis, often having to convert again to figure out the original categories. This is painfully slow, with the state of the art being measured in hours. If we could shift that analysis left, process the original categorical data as it streams in, without modification, that could cut mean time to insight down to seconds, and possibly save financial institutions some large dollar signs. That could also enable many other options, such as using graph NLP on flowing data, finding novel behavior, detecting anomalies such as cyber-attacks before they affect systems. The speed of an in-line data processing engine like Flink or KsqlDb combined with graph algorithms and categorical analysis is uniquely powerful. Come learn about a new open source streaming intelligence system that changes the game for risk analysis and other fast categorical data processing.
Location: Boston Date : May 09, 2023 - May 10, 2023 Organizer: DBTA
Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
There are a lot of advantages to moving to the cloud. But the more various organizations move to the cloud, the more we see them tripping over hidden land mines like out-of-control costs, platform lock-in that restricts future options, regulations that restrict data location, etc. How can a company shift data analysis workloads into the cloud, while minimizing their exposure to those risks?
In this session, you will learn how to:
• transition to the cloud, while keeping some workloads on prem,
• move to multiple clouds without hopelessly complicating analytics
• maintain high throughput and low latency in cloud analytics
• keep platform options for the future open
Location: Las Vegas Date : March 27, 2023 - March 29, 2023 Organizer: IWCE
Use AIOps to Improve Uptime and Reduce Mean Time to Repair
Hardware breaks. While a lot of industries talk about going to the cloud – aka someone else’s hardware – to solve uptime issues, this doesn’t work so well when you ARE someone’s hardware provider. Whether you’re a telecom company with towers and networks, a computer infrastructure company, an energy utility, a manufacturing company, or even a car company – anyone who provides solid metal hardware needs to make sure it keeps running.
AIOps is the smart application of advanced analytics including machine learning to monitor, and in many cases fix IT related problems before the end user is even aware of them. A good example has embedded analysis capability that can improve the productivity of support technicians. A wide variety of industries are getting similar benefits by embedding the ability to analyze IoT data. Telecom is another industry with a constant need to monitor traffic, automatically identify overloaded areas, and reroute calls to prevent outages or dropped calls. Where should your next tower go? How can the flood of 5G data be captured, managed, and put to use, without overloading staff or technology?
In every industry, the key question is: How can I find and fix issues before anyone is aware of the problem, or at least vastly reduce the mean time to repair those issues that do occur? AIOps holds the key. Harness the flood of IoT data to catch and prevent incidents before they happen or fix them as soon as possible after they happen.
This sounds amazing as a concept, but how do companies implement this? What is involved? What gotchas hide in the details? With examples from leaders in multiple industries, this presentation will help you learn:
What is AIOps and what can you expect from a solid implementation
Benefits AIOps provides in various use cases: predictive maintenance, performance optimization, network bottleneck identification and remediation, MTTR reduction, etc.
Example implementations - problems you are likely to run into, requirements to make it work, tradeoffs you need to consider, etc.
Location: Austin, Texas Date : June 13, 2022 - June 13, 2022 Organizer: Global Data Geeks
What is Data Day Texas?
Originally launched in January 2011 as one of the first NoSQL / Big Data conferences, Data Day Texas each year highlights the latest tools, techniques, and projects in the data space, bringing speakers and attendees from around the world to enjoy the hospitality that is uniquely Austin. Since its inception, Data Day Texas has continually been the largest independent data-centric event held within 1000 miles of Texas. Our most recent editions have drawn over 1000 attendees.
Location: Boston Date : May 17, 2022 - May 18, 2022 Organizer: DBTA
THE DATA MANAGEMENT AND ANALYTICS CONFERENCE
We're excited to welcome our community of data professionals back to Boston this May for three days of practical advice, inspiring thought leadership, and in-depth training. Join your peers to learn, share, and celebrate the trends and technologies shaping the future of data. See where the world of big data and data science is going, and how to get there first.
At Data Summit 2022, you’ll hear the innovative approaches the world’s leading companies are taking to solve today’s key challenges in data management. Whether your interests lie in the technical possibilities and challenges of new and emerging technologies or using Big Data for business intelligence, analytics, and other business strategies, Data Summit 2022 has something for you!
You can expect to leave Data Summit 2022 with new friends and business allies and actionable advice and strategies for moving your business forward. Please join us in Boston, MA this May for this career- and organization-changing opportunity.
Location: London, UK Date : September 21, 2021 - September 22, 2021 Organizer: Andrew Steed
THE UK’S LARGEST DATA & ANALYTICS EVENT
Big Data LDN (London) is the UK’s largest free to attend data & analytics conference and exhibition, hosting leading data and analytics experts, ready to arm you with the tools to deliver your most effective data-driven strategy.
Discuss your business requirements with over 130 leading technology vendors and consultants. Hear from 180+ expert speakers in 8 technical and business-led conference theatres, with real-world use-cases and panel debates.
Network with your peers and view the latest product launches & demos.
Big Data LDN attendees have access to free on-site data consultancy and interactive evening community meetups.
Register free for Big Data LDN and learn how to build a bright data-driven future for your business.
Location: https://dscamp.org/ Date : July 22, 2022 - July 22, 2022 Organizer: Ross Chayka
3 Streams
A rich program and lots of content
30 Speakers
Industry professionals will tell you the most important thing
500 Participants
The conference brings together participants from all over the world
Location: https://dssconf.pl/ Date : June 21, 2022 - June 22, 2022 Organizer: Data Science Warsaw
The leading conference in Poland for data science professionals and fans - 2022 is hybrid
Data Science Summit is the largest and oldest (1st edition in 2016), independent data science conference in the CEE Region.
The conference is additionally accompanied by the Data Science Expo – a part with stands of data science technology / solution providers and currently recruiting employers.
Location: Vilnius, Lithuania Date : September 28, 2021 - September 29, 2021 Organizer: Vaida Lazareviciute
ABOUT THE CONFERENCE
Big Data Conference Europe is a three-day conference with technical talks in the fields of Big Data, High Load, Data Science, Machine Learning and AI.
Conference brings together developers, IT professionals and users to share their experience, discuss best practices, describe use cases and business applications related to their successes.
The event is designed to educate, inform and inspire – organized by people who are passionate about Big Data and Data Exploration. We look forward to seeing you there!
Location: Los Angeles, California Date : September 17, 2021 - September 19, 2021 Organizer: Soubash D'Souza
The Largest Data Conference in Southern California.
Spearheaded by Subash D’Souza and organized and supported by a community of volunteers, sponsors and speakers, Data Con LA features the most vibrant gathering of data and technology enthusiasts in Los Angeles.
Data Con LA began as Big Data Camp LA in 2013, with just over 250 attendees. It was rebranded to Big Data Day LA in 2014 with over 550 attendees in 2014, 950+ attendees in 2015, 1200+ attendees in 2016, and 1550+ attendees in 2017. In 2018, we re-branded ourselves from Big Data Day LA to Data Con LA with over 1800 attendees and over 2000 in 2019. In response to the COVID-19 pandemic, DCLA had its first successful virtual conference in 2020 with over 1000 virtual attendees.
Join Thinkers360 for free! Are you a Reader/Writer, Thought Leader/Influencer (looking to increase your earnings), or an Enterprise User (looking to work with experts)?




 Hazelcast Platform Essentials
Hazelcast Platform Essentials
 GridGain Developer Essentials: Apache Ignite
GridGain Developer Essentials: Apache Ignite
 IASA CITA-Foundation
IASA CITA-Foundation
 Women in Architecture
Women in Architecture
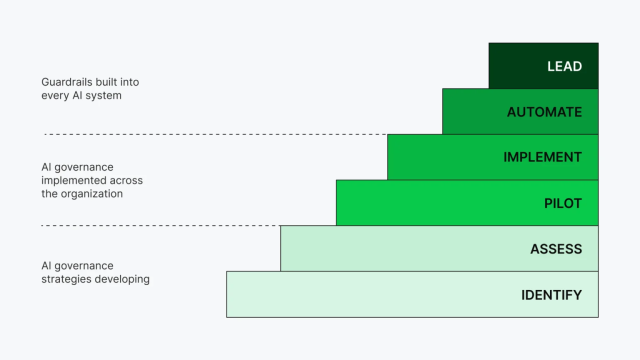 AI Governance Guide: Building Trust into Your Platform
AI Governance Guide: Building Trust into Your Platform
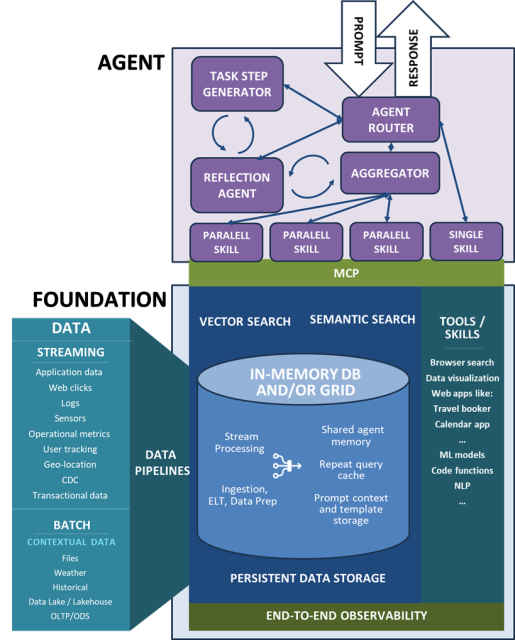 Architecting a Modern Data Stack for AI Agents
Architecting a Modern Data Stack for AI Agents
 Streaming vs Batch, Lakehouse, and Data Architectures of the Future
Streaming vs Batch, Lakehouse, and Data Architectures of the Future
 https://medium.com/@paigeonthewing/gen-ai-writing-theft-and-llms-eating-their-own-tails-7789a16a04d5
https://medium.com/@paigeonthewing/gen-ai-writing-theft-and-llms-eating-their-own-tails-7789a16a04d5
 Gen AI, Writing, Theft, and LLMs Eating Their Own Tails
Gen AI, Writing, Theft, and LLMs Eating Their Own Tails
 Agentic AI is the New Internet
Agentic AI is the New Internet
 APTs are Everywhere — Why my piddly site keeps getting Cyrillic junk comments and attacks from Singapore
APTs are Everywhere — Why my piddly site keeps getting Cyrillic junk comments and attacks from Singapore
 When Linear Scaling is Too Slow—Build for Fast Hardware
When Linear Scaling is Too Slow—Build for Fast Hardware
 When Linear Scaling is Too Slow - Compress Your Data
When Linear Scaling is Too Slow - Compress Your Data
 When Linear Scaling is Too Slow - Share Nothing
When Linear Scaling is Too Slow - Share Nothing
 When Linear Scaling is Too Slow: Isolate Your Workloads
When Linear Scaling is Too Slow: Isolate Your Workloads
 When Linear Scaling is Too Slow — The last strategy you should use.
When Linear Scaling is Too Slow — The last strategy you should use.
 What’s New in OpenText Analytics Database
What’s New in OpenText Analytics Database
 Busting Cloud Myths and Avoiding Cloud Pitfalls
Busting Cloud Myths and Avoiding Cloud Pitfalls
 AIOps: 4 Common Challenges and 3 Key Considerations for Using AI in IT Operations
AIOps: 4 Common Challenges and 3 Key Considerations for Using AI in IT Operations
 What Does Real-time Really Mean In Data Analytics?
What Does Real-time Really Mean In Data Analytics?
 Consider Performance, Growth & Budget When Buying Data Analytics
Consider Performance, Growth & Budget When Buying Data Analytics
 Save the Planet with Better Software — Vertica Analytics for ESG
Save the Planet with Better Software — Vertica Analytics for ESG
 Is Cloud Repatriation a Big Lie Server Vendors Are Shilling?
Is Cloud Repatriation a Big Lie Server Vendors Are Shilling?
 Why Can’t We Have AI-Driven Database Design?
Why Can’t We Have AI-Driven Database Design?
 Five Reasons Why In-Database Machine Learning Makes Sense
Five Reasons Why In-Database Machine Learning Makes Sense
 New O’Reilly Book: Accelerate Machine Learning with a Unified Analytics Architecture
New O’Reilly Book: Accelerate Machine Learning with a Unified Analytics Architecture
 What’s the Difference Between a Data Lakehouse and a Unified Analytics Platform?
What’s the Difference Between a Data Lakehouse and a Unified Analytics Platform?
 It’s a Trap! — Cloud Financial Incentive for Badly Optimized Analytics Software
It’s a Trap! — Cloud Financial Incentive for Badly Optimized Analytics Software
 What Do People Mean by “Cloud-Native?”
What Do People Mean by “Cloud-Native?”
 Container Boom: Should Databases Be Containerized?
Container Boom: Should Databases Be Containerized?
 Moving to real-time stream processing-some basics
Moving to real-time stream processing-some basics
 Aerospike Up and Running
Aerospike Up and Running
 Accelerate Machine Learning with a Unified Analytics Architecture
Accelerate Machine Learning with a Unified Analytics Architecture
 97 Things Every Data Engineer Should Know
97 Things Every Data Engineer Should Know


 Faster Time-to-Value with In-Database Machine Learning
Faster Time-to-Value with In-Database Machine Learning
 Architecting for Speed & Scale - Get Consistency & Real-Time Latency With a DIH
Architecting for Speed & Scale - Get Consistency & Real-Time Latency With a DIH
 Unlocking the Power of Real-Time Data and Analytics
Unlocking the Power of Real-Time Data and Analytics
 Streaming Graph Processing on Categorical Data Enables Real-time Risk Calculation
Streaming Graph Processing on Categorical Data Enables Real-time Risk Calculation

 Shift Difficult Problems Left with Graph Analysis on Streaming Data
Shift Difficult Problems Left with Graph Analysis on Streaming Data
 When linear scaling is too slow – strategies for high scale data processing
When linear scaling is too slow – strategies for high scale data processing
 Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
 Use AIOps to Improve Uptime and Reduce Mean Time to Repair
Use AIOps to Improve Uptime and Reduce Mean Time to Repair
 Build analytics for performance and growth on a budget
Build analytics for performance and growth on a budget
 Get Projects into Production Faster with In-DB ML
Get Projects into Production Faster with In-DB ML
 Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
Reduce Risk and Avoid Lock-in When Moving from On-Prem to Cloud or Hybrid
 Achieving Unified Analytics
Achieving Unified Analytics


 Unifying Analytics - Production Analytics Architecture Evolution
Unifying Analytics - Production Analytics Architecture Evolution
 Unifying Analytics: Architecting Production IOT Analytics
Unifying Analytics: Architecting Production IOT Analytics
 Unapologetically Technical
Unapologetically Technical
 InsightJam - Where Will Agentic AI Advance the Most in the Next 1-3 Years?
InsightJam - Where Will Agentic AI Advance the Most in the Next 1-3 Years?
 The Race to Unified Analytics: Next-Gen Data Platforms and Architectures
The Race to Unified Analytics: Next-Gen Data Platforms and Architectures
 Unlock the Value in Data: Rise of Hybrid Cloud, Multi-Cloud Platforms
Unlock the Value in Data: Rise of Hybrid Cloud, Multi-Cloud Platforms
 Cloud Without Compromises: Crucial Analytical Data Platform Requirements
Cloud Without Compromises: Crucial Analytical Data Platform Requirements
 Find the Balance Between MPP Databases and Spark for Analytical Processing
Find the Balance Between MPP Databases and Spark for Analytical Processing
 Thought Leadership: Modernize Data Warehousing – Beyond Performance
Thought Leadership: Modernize Data Warehousing – Beyond Performance
 Natural Language Processing Augmented Analytics
Natural Language Processing Augmented Analytics
















 Paige Roberts
Paige Roberts
 DBTA Data Summit
DBTA Data Summit
 IWCE
IWCE
 Data Day Texas
Data Day Texas
 DBTA Data Summit
DBTA Data Summit
 Big Data London
Big Data London
 Data Science Online Camp 2022
Data Science Online Camp 2022
 Data Science Summit Poland
Data Science Summit Poland
 Big Data Conference Europe
Big Data Conference Europe
 DataCon LA
DataCon LA


